Создание прогнозов с помощью модуля машинного обучения
Продолжая работать с платформой SberMobile и разрабатывая свое приложение, вы, возможно, захотите использовать инструменты для анализа данных и прогнозирования. Одним из таких полезных инструментов является модуль машинного обучения. В следующем примере показано, как использовать алгоритм линейной регрессии для создания модели, предсказывающей связь между независимой и зависимой переменными. В данном случае мы будем прогнозировать количество собранной энергии (зависимая переменная) на основе среднесуточной люминесценции (зависимая переменная). Понимая эту взаимосвязь, мы сможем делать более точные прогнозы относительно будущего производства энергии и выявлять потенциальные проблемы или возможности для улучшения. В этой главе мы продемонстрируем возможность использования линейной регрессии для создания модели прогнозирования выработки электроэнергии на основе данных о люминесценции, полученных от электростанции на солнечных батареях.
Существует несколько различных алгоритмов, доступных в модуле Машинное обучение, и все они имеют схожую схему использования. Ниже мы рассмотрим основные этапы работы:
Подготовка соответствующих наборов данных
Создание структуры данных в SberMobile для задач машинного обучения
Создание и настройка обучаемого модуля SberMobile
Обучение обучаемого модуля
Тестирование обучаемого модуля
Генерирование прогнозов на основе обучаемых модулей
Отображение прогнозов на инструментальных панелях
Подготовка соответствующих наборов данных
Чтобы делать прогнозы и решать другие задачи машинного обучения, например, классификацию, мы можем обучить математическую модель на основе имеющихся данных. Мы будем делать прогнозы на основе ежедневных исторических значений люминесценции для региона, где расположена наша электростанция, и общей выработки энергии за этот день.
В следующем примере данные находятся в файле, элементы которого разделены точкой с запятой. В используемом нами наборе данных около 500 пар значений. Наш файл выглядит следующим образом:
luminescence;energy
0.267027698;32.54661902
0.976869989;55.39033824
3.664669577;71.16015301
3.986523168;131.6570175
4.236464973;118.8121496
4.865873622;188.1513313
...
и т.д.
...В первую очередь необходимо рассмотреть разделение набора данных на обучающие и контрольные. Обучающие данные - это то, что будет использоваться для создания математической модели прогнозирования, а контрольные данные - это то, что мы будем использовать для проверки точности модели. Тестовые и обучающие данные должны быть разными, иначе мы не сможем определить, когда наша модель слишком переоснащена. Можно сказать, что модель слишком точно соответствует обучающему набору данных.
Мы будем использовать математически простую модель линейной регрессии, в которой переобучение обычно не является проблемой, если только нет достаточного количества точек данных относительно параметров модели. Подробное обсуждение математики выходит за рамки этого документа, но в данном примере 500 точек данных более чем достаточно для одного параметра прогнозирования.
Обучающие данные
Мы случайным образом выбираем 70 % строк из нашего набора данных и создаем документ с примерно 350 точками данных, отформатированный следующим образом:
luminescence;energy
0.267027698;32.54661902
0.976869989;55.39033824
3.664669577;71.16015301
... еще 350 точек данныхКонтрольные данные
Оставшиеся 30 % строк нашего набора данных образуют документ, содержащий около 150 строк:
luminescence;energy
3.986523168;131.6570175
4.236464973;118.8121496
4.865873622;188.151331
...еще 150 точек данныхСоздание структур данных для задач машинного обучения
Теперь, когда у нас есть обучающие и контрольные наборы данных, нам нужно создать правильные структуры данных в SberMobile. В контекстном меню узла Модели в системном дереве выберите Создать.
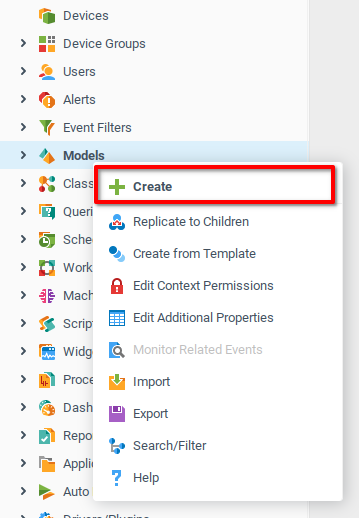
Добавьте подходящие имя и описание для модели и нажмите OK.
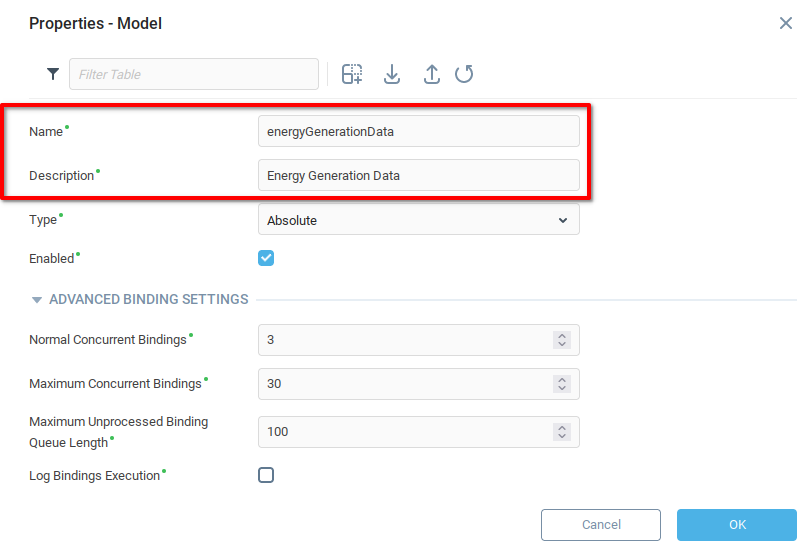
В появившемся окне Конфигурация модели :
Выберите вкладку Переменные модели.
Добавьте две строки в таблицу.
Добавьте соответствующие имена и описания переменных для обучающего и контрольного наборов данных.
Установите для обеих переменных значение Изменяемая.
Откройте вложенную таблицу с детальной информацией в поле Формат (это нужно сделать для обеих переменных).
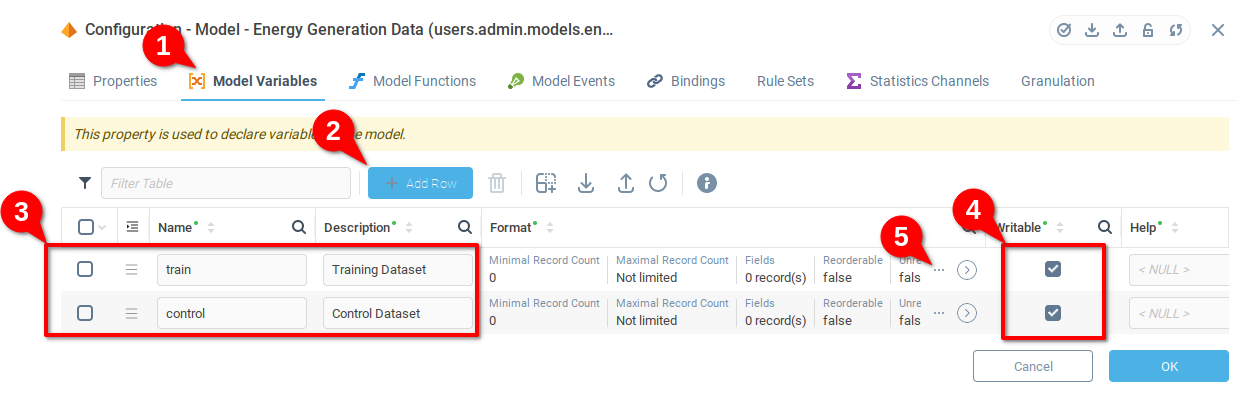
Далее откройте сведения о полях.
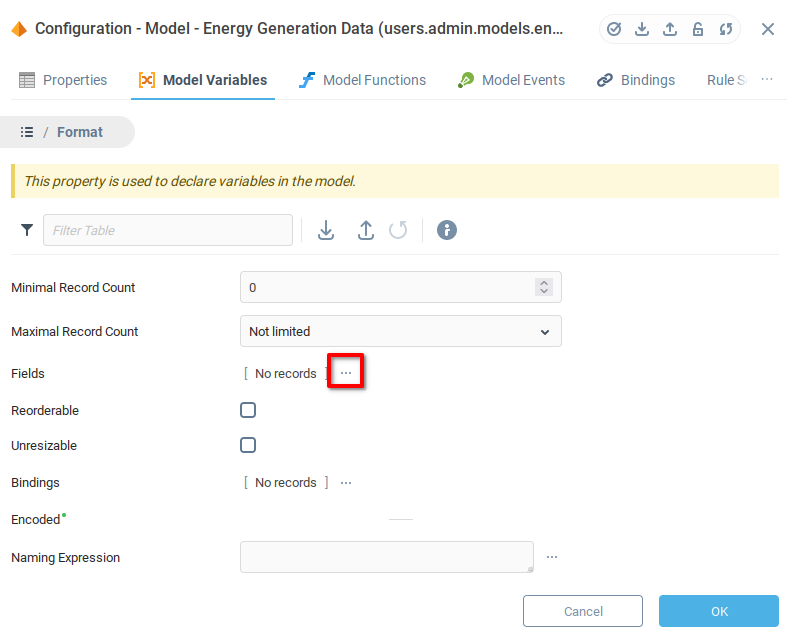
В списке полей:
Добавьте два поля.
Добавьте соответствующее имя (и описание, если нужно).
Установите для обоих полей тип Float.
Установите флаг Может быть NULL, чтобы оба поля могли принимать значение Null.
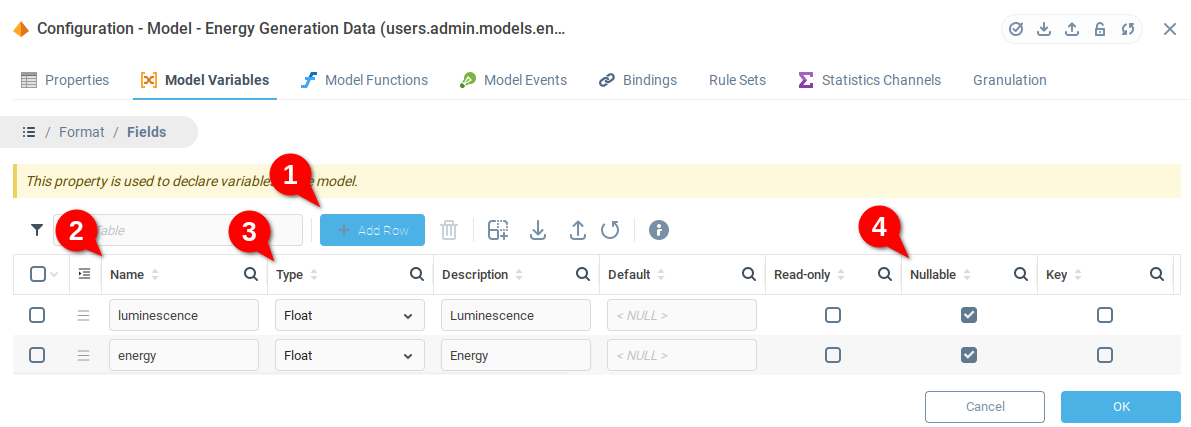
После добавления полей Luminescence и Energy в переменную Train повторите предыдущие шаги для переменной Control.
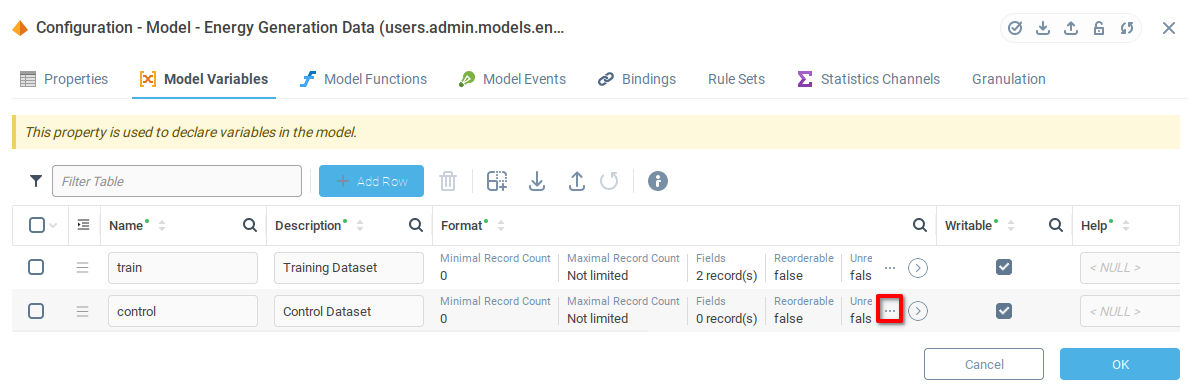
После добавления полей Luminescence и Energy в переменную Control сохраните изменения и нажмите кнопку OK.
Загрузка данных в модель
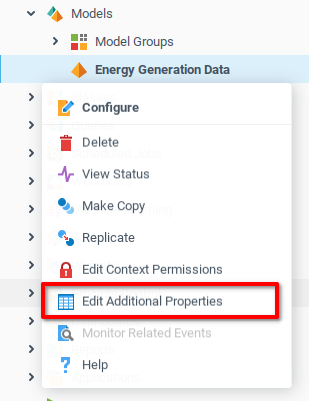
Теперь, когда в модели созданы соответствующие переменные, в контекстном меню модели, которую вы создали на предыдущем шаге, выберите Редактировать дополнительные свойства.
Мы видим переменные, созданные на предыдущем шаге, Control Dataset и Training Dataset. Разблокируйте переменные для редактирования (1), а затем откройте Training Dataset (2).
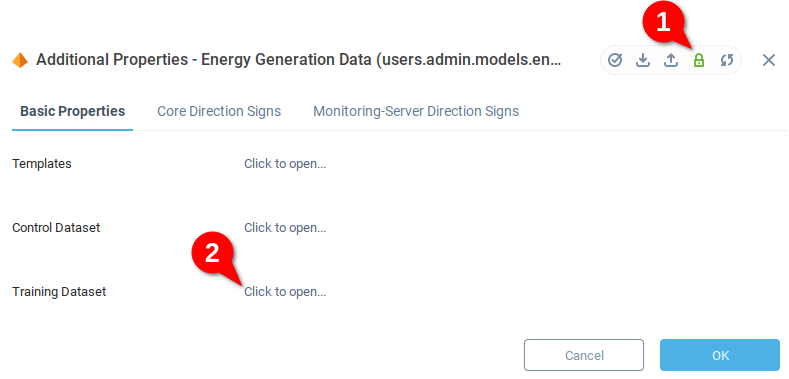
Данные не были добавлены, поэтому таблица пуста. Выберите значок импорта данных - импортировать файл. Загрузите данные для обучающей выборки.
Если импорт прошел успешно, поле должно быть заполнено обучающими данными. Нажмите OK, чтобы сохранить изменения и закрыть окно.
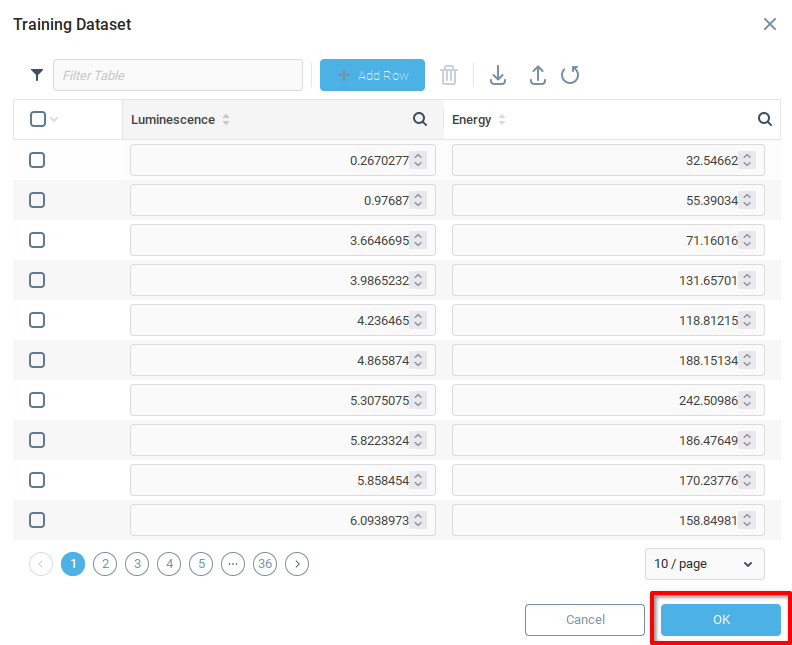
Повторите описанные выше действия для контрольного набора данных, убедившись, что загружены правильные данные.
Создание и настройка обучаемого модуля
Теперь, когда у нас есть модель с обучающими и контрольными данными, следующим шагом будет настройка обучаемого модуля. Обучаемый модуль является дочерним элементом контекста Машинное обучение, и каждый экземпляр обучаемого модуля представляет собой одну модель, использующую определенный алгоритм и гиперпараметры.
В контексте Машинное обучение откройте контекстное меню и выберите Создать.
Откройте менюСвойства обучаемого модуля:
Добавьте подходящие Имя и Описание, выберите значения Регрессия и Линейная регрессия в полях Задача и Алгоритм соответственно.
Укажите имя переменной, для которой необходимо сделать прогноз. В нашем примере мы хотим предсказать количество выработанной энергии на основе люминесценции. Когда мы отправляем данные в модель для обучения, тестирования или генерации прогнозов, в них должен присутствовать столбец с именем
energy, иначе модуль вернет ошибку. В модели, созданной на предыдущем шаге, есть столбцы с именамиluminescenceиenergy.
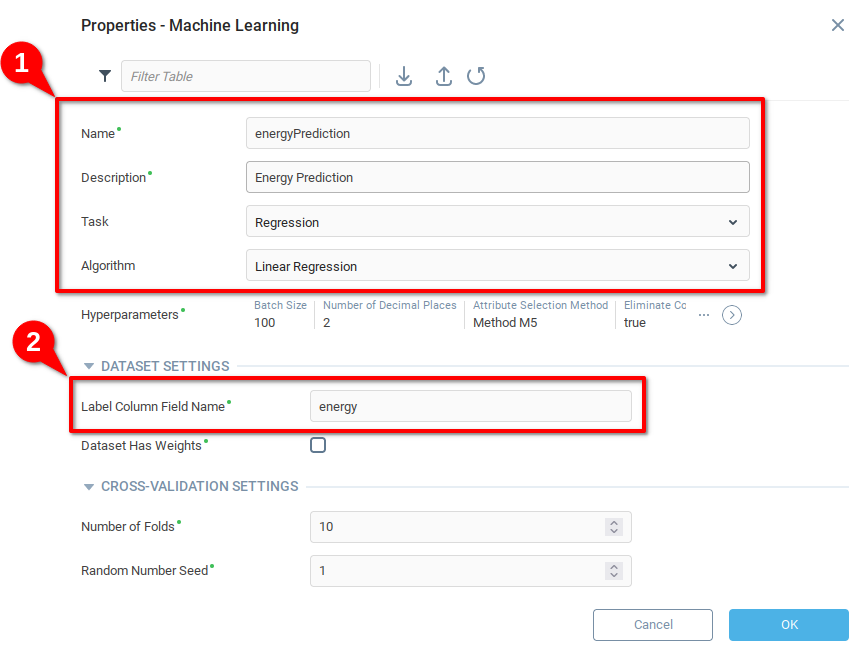
Нажмите OK, чтобы сохранить изменения и закрыть модель. Теперь наш обучаемый модуль готов к обучению.
Обучение и тестирование обучаемого модуля
Чтобы обучить и протестировать обучаемый модуль, который мы создали на предыдущем шаге, нам нужно создать функции "обучить" и "оценить" для этого модуля. Сначала мы создадим функции в модели Energy Generation Data, чтобы показать, как можно использовать язык выражений для работы с обучаемым модулем.
Выберите опцию Настроить из контекстного меню модели Energy Generation Data.
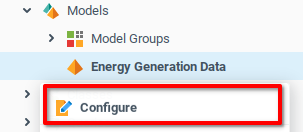
Откройте меню Конфигурация модели:
Перейдите на вкладку Функции модели.
Добавьте три строки в таблицу функций.
Добавьте имена и описания для функций. В приведенном ниже примере для трех функций используются слова
train,evaluateиoperate.Прокрутите страницу вправо, чтобы найти поле Выражение.
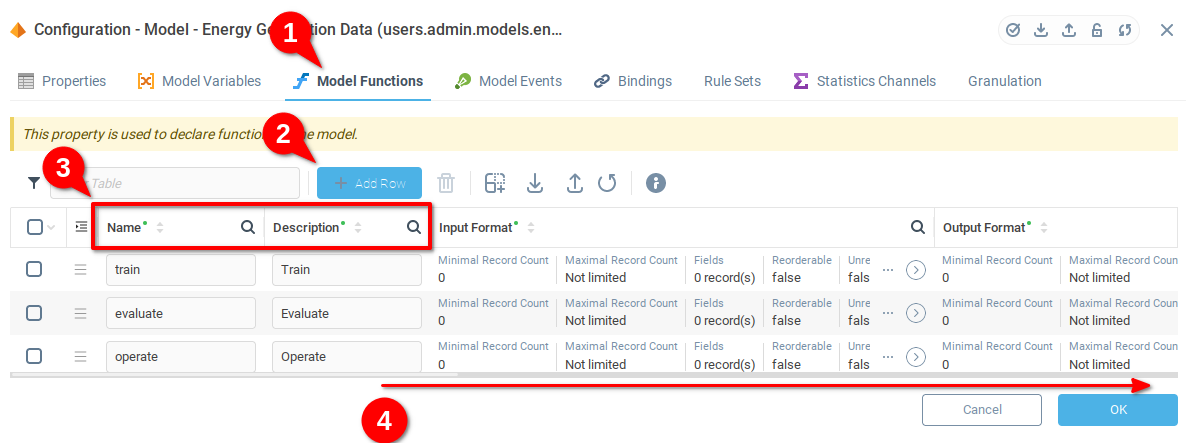
Поле Выражение позволяет нам определить выражение, которое будет выполняться при вызове функции модели. Для демонстрации мы используем функции модели, но вы можете использовать функцию callFunction() из списка функций, относящихся к контексту в любом выражении в SberMobile. Это позволит вам полностью автоматизировать использование обучаемых моделей.
На вкладке Функции модели вы можете увидеть поле Выражение для каждой из функций. Ниже мы опишем выражения, которые нужно добавить в каждую строку.
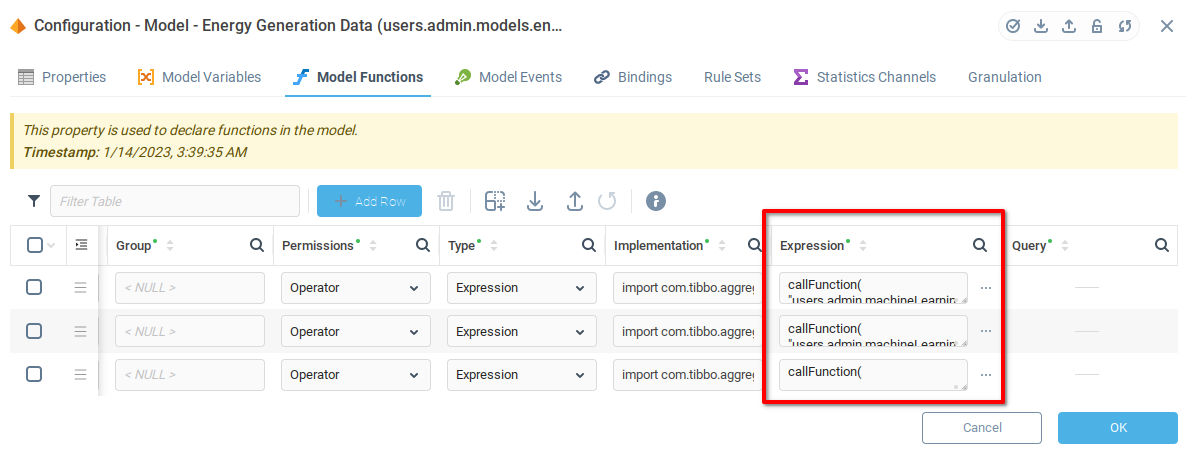
Как упоминалось выше, для обучаемого модуля мы будем использовать функцию языка выражений callFunction(), относящейся к контексту. Первые два параметра функции callFunction() - это путь к контексту, из которого мы хотим вызвать функцию, и имя функции. Остальные параметры определяются вызываемой функцией. В случае с тремя функциями обучаемого модуля, единственным оставшимся параметром является таблица с данными для обучения, оценки или работы.
Наведите курсор мыши на окно конфигурации обучаемого модуля, чтобы найти контекстный путь. Мы нашли контекстный путь users.admin.machineLearning.energyPrediction для нашего обучаемого модуля.

Следующий параметр функции callFunction() - это имя функции, которую мы хотим вызвать. Из документации про Обучаемый модуль мы знаем, что есть три функции, которые нужно использовать: train - для обучения модели, evaluate - для оценки точности модели, и operate - для получения реального прогноза с помощью модели.
Наконец, возникает вопрос, откуда мы будем брать данные. Помня, что мы назвали переменные в модели train и control, и зная, что контекстный путь для модели users.admin.machineLearning.energyPrediction, мы можем задать путь к переменной с помощью оператора : и заключить результат в скобки {}.
Для доступа к обучающим данным мы будем использовать {users.admin.models.energyGenerationData:train}, а к контрольным данным - {users.admin.models.energyGenerationData:control}. Соединив все элементы вместе, мы получим следующие выражения, которые нужно поместить в поле Выражение функции модели:
Train
callFunction(
"users.admin.machineLearning.energyPrediction",
"train",
{users.admin.models.energyGenerationData:train}
)Evaluate
callFunction(
"users.admin.machineLearning.energyPrediction",
"evaluate",
{users.admin.models.energyGenerationData:control}
)Operate
callFunction(
"users.admin.machineLearning.energyPrediction",
"operate",
{users.admin.models.energyGenerationData:control}
)Теперь, когда функции созданы, мы можем вызывать их из контекстного меню модели Energy Generation Data. Сначала обучим модель, вызвав функцию Train.
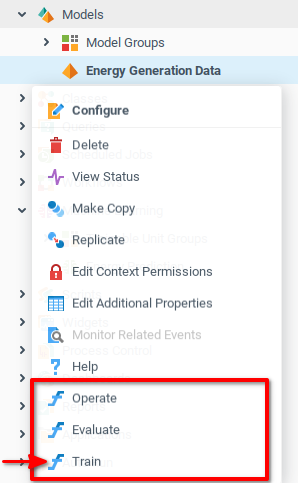
После обучения модели нам будут представлены некоторые данные, связанные с точностью модели. Поскольку мы используем линейную регрессию, модель представляет точную формулу, полученную в результате выполнения регрессии по обучающим данным. Каждая модель возвращает информацию, специфичную для используемого алгоритма.
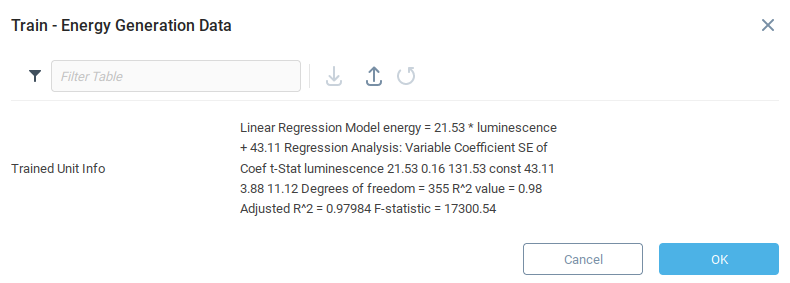
Теперь, когда мы обучили модель, мы можем проверить ее на точность. Снова откройте контекстное меню модели Energy Generation Data, но теперь выберите функцию Evaluate и подтвердите операцию.
Функция Evaluate обучающего модуля выдает ряд показателей, связанных с точностью модели.
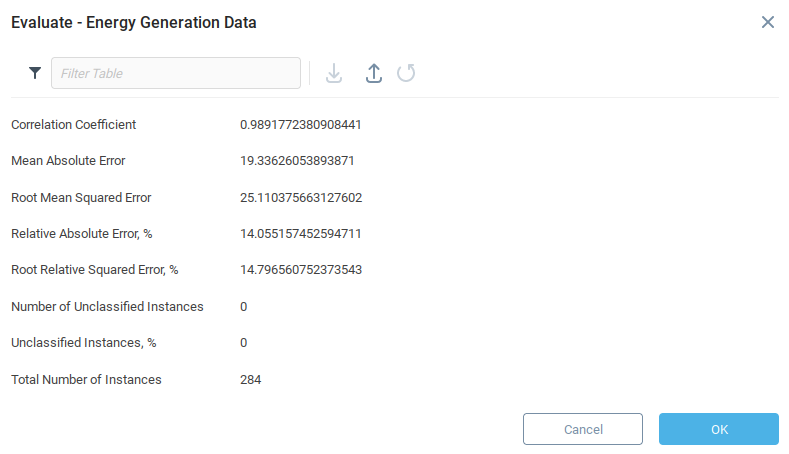
Теперь, когда модель обучена, и мы убедились, что значения погрешностей удовлетворительные, мы можем использовать модель для составления прогнозов.
Получение прогнозов от обучаемого модуля
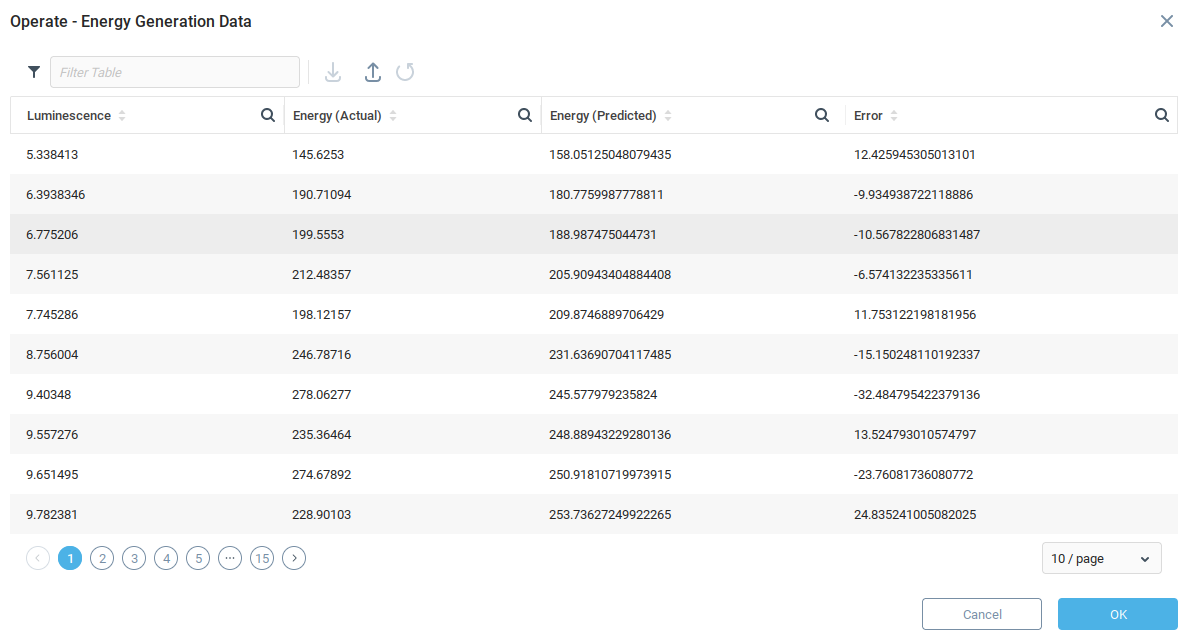
Для получения прогнозов от обучаемого модуля требуются данные в том же формате, что и обучающие данные. В рассматриваемом примере мы пока что делаем прогнозы на основе контрольных данных, поскольку они уже имеют правильный формат. Вызовите функцию Operate из контекстного меню модели Energy Generation Data.
Функция operate берет предоставленные данные и генерирует прогнозы с помощью модели, сравнивает прогнозы с фактическими значениями и отображает значения ошибок. Поскольку мы использовали контрольные данные, то фактические значения уже имеются. На практике фактическое значение будет равно нулю.
Дальнейшее изучение
Теперь, когда у вас есть общее представление о том, как использовать обучаемый модуль, вы можете изучить следующую информацию:
Добавление полученных прогнозов в виде диаграммы на инструментальную панель.
Использование различных алгоритмов для обучаемых модулей.