Эффективный и читабельный код
Важность эффективного и читаемого кода трудно переоценить (а также конфигурации лоу кода). Он является краеугольным камнем поддерживаемого и масштабируемого программного обеспечения. Четкий и понятный код упрощает отладку и усовершенствование, а также способствует сотрудничеству между разработчиками.
Работа с чувствительностью данных и конфигураций с помощью переменных
Не рекомендуется встраивать конфиденциальные данные, такие как ссылки, пароли и имена пользователей, непосредственно в код. Текущая практика может привести к уязвимостям в системе безопасности и проблемам с обслуживанием. Например, при изменении пути к контексту на распределенном сервере обновление каждого жестко закодированного экземпляра может быть сопряжено с ошибками и отнимать много времени. Ниже приведен пример плохой практики с жестко закодированными значениями для функции:
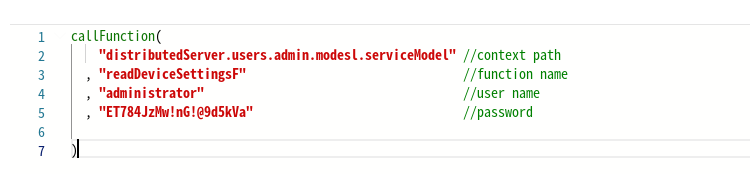
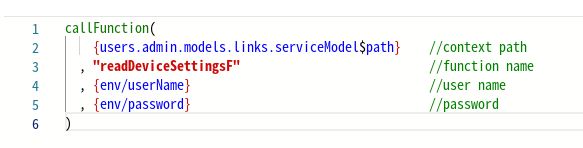
Чтобы повысить удобство обслуживания и безопасность, храните такую информацию в переменных. Возьмем, к примеру, путь контекста на распределенном сервере: назначив его переменной, любые будущие изменения требуют только одного обновления, что обеспечивает согласованность и снижает риск возникновения ошибок во всем приложении.
Удаление закомментированных фрагментов кода из выражений
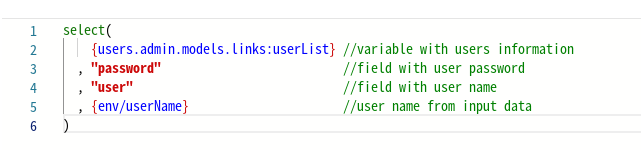
Для отладки выражений иногда необходимо заменить переменные окружения прямыми ссылками. Поскольку процесс отладки может занять несколько итераций, разработчики часто используют одновременно две или более версий кода, одна из которых активна, а остальные заключены в блоки комментариев. Обязательно удалите такие закомментированные части кода после отладки, чтобы избежать уязвимости приложения, особенно если закомментированный блок содержит конфиденциальные данные, такие как имена пользователей, пароли и так далее. На изображении ниже показан закомментированный блок, который необходимо удалить после завершения отладки:
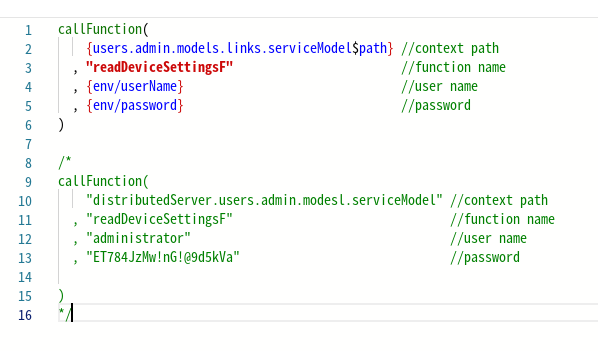
Использование табуляции и перевода строки для вложенных функций
Использование табуляции и переноса строк важно для ясности вложенных функций и списков аргументов при написании выражений. Код легче понять, если использовать табуляции и переносы строк для разграничения слоев вложенности, аргументов функций и так далее.
Выражения расширенного поиска часто содержат несколько функций с несколькими аргументами. Запись всех аргументов в одной строке без четкого разделения делает выражение громоздким:

На первый взгляд трудно понять, какие функции и аргументы используются в выражении, но если разумно использовать табуляцию и переносы строк для каждой вложенной функции, код можно переписать так, чтобы его было легче понять:

Размещение аргументов функции в колонке
Большинство функций в языке выражений требуют аргументов. В описании каждой функции возможные аргументы записываются в одну строку через запятую. Если аргументов три или меньше и каждый из них относительно короткий, их можно перечислить в одной строке кода выражения. Однако указание аргументов функции в столбце может сделать ее более читаемой и простой в обслуживании. Среди преимуществ - возможность быстро увидеть количество аргументов, увидеть, где они начинаются и останавливаются, легко закомментировать некоторые аргументы для быстрой отладки и добавить комментарии для каждого аргумента. По традиции в начале строки ставятся запятые "," и оператор конкатенации строк "+", чтобы указать начало новых аргументов или продолжение строки с предыдущей строки.
Вот несколько примеров:
Предположим, что одна таблица в выражении основана на другой таблице. В результате аргументов у функции много, и их перечисление в одной строке затруднит чтение кода:

Перечисление аргументов в столбце делает код гораздо более читабельным. Строка, определяющая таблицу, разбивается на две строки с помощью оператора конкатенации "+", а последующие аргументы записываются в отдельной строке:
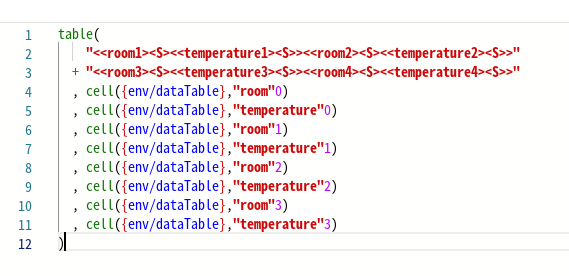
Символ запятой "," в начале строки помогает определить, какие и сколько аргументов используются в функции. При отладке каждый аргумент в отдельной строке позволяет при необходимости закомментировать его или вставить в аргументы функции различные значения:

Разбивайте длинные строки
Аргументы многих функций задаются в виде строк на языке выражений. Аргументы с длинными строками могут затруднить чтение выражений. В таких случаях разбиение длинной строки на несколько более коротких может упростить написание, отладку и обслуживание выражений. Чтобы разделить строковое выражение, поставьте закрывающую кавычку в соответствующем месте, используйте оператор конкатенации "+" и открывающую кавычку перед остальной частью текста. Текущий метод очень удобен для разделения аргументов функций, содержащих длинные строки. Возьмем, к примеру, функцию с длинной строкой:
exampleFunction("Предположим, что это очень длинная строка, которая просто продолжается и продолжается, и никто не знает, где она остановится, если только не прокрутить ее до конца строки").Предыдущая функция может быть разбита на несколько строк следующим образом:
exampleFunction("предположим, что это очень длинная строка, которая просто продолжается и продолжается, и продолжается, "
+ "никто не знает, где она остановится, если не прокрутить ее до конца строки").Следующий пример иллюстрирует разделение строк при работе с SQL-запросом. Запрос может ссылаться на набор контекстов, таблиц данных, переменных и многое другое. Если поместить их в одну строку, запрос станет громоздким. Разбиение длинной строки запроса на несколько более коротких сделает код более читабельным и упростит дальнейшее сопровождение и отладку. Размещение каждой переменной на новой строке позволяет быстро прокомментировать, добавить, удалить или точно заменить любую строку:
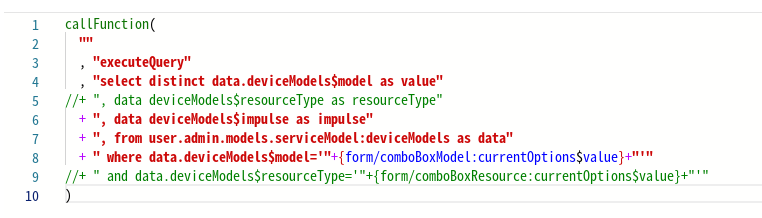
Используйте одинарные кавычки для внешних строк и двойные кавычки для внутренних строк.
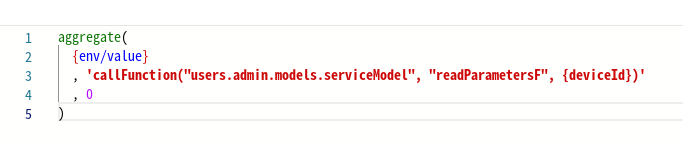
Когда вы пишете выражения, принято использовать одинарные кавычки для внешних строк и двойные кавычки для строк, вложенных внутрь. Текущий подход упрощает вложенность функций и минимизирует конфликты кавычек.
Использование одинарных кавычек для внешнего слоя и двойных кавычек для внутренних строк гарантирует, что внутренняя строка будет интерпретироваться буквально, не будучи обработанной как часть кода, который ее окружает. Кроме того, подобная практика облегчает включение функций или выражений, не усложняя процесс экранирования кавычек.
Вот пример, демонстрирующий использование одинарных и двойных кавычек:
Декомпозиция сложных выражений
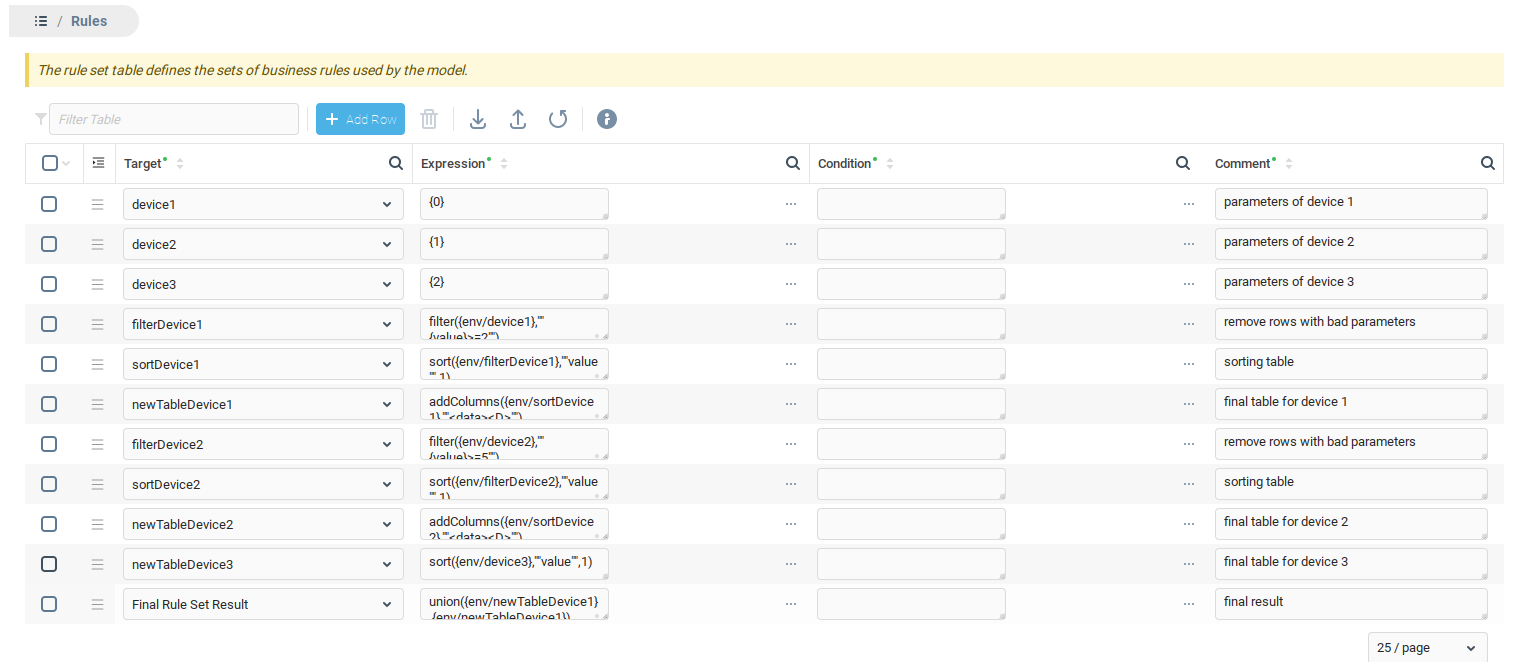
Иногда табуляции и переноса строк недостаточно, чтобы внести ясность, особенно в выражениях, содержащих множество функций, вложенных и последовательных операций. На определенном уровне сложности рассмотрите возможность разбиения одного сложного выражения на наборы правил внутри модели. Сложное выражение можно декомпозировать на более простые части, что в свою очередь упрощает как разработку, так и обслуживание требуемой функциональности.
Пример декомпозиции
Предположим, что реализация функции подразумевает несколько последовательных действий. Если записать функцию в одну строку, то выражение будет выглядеть следующим образом, и его будет довольно сложно понять человеку:

Даже если ввести несколько строк и использовать табуляцию для отображения иерархии, выражение получается довольно громоздким. Текущее выражение можно разложить на отдельные части и выразить в виде набора правил. Как показано ниже, каждая часть выражения была разделена на шаги в наборе правил, причем каждый шаг четко прокомментирован с описанием его цели.